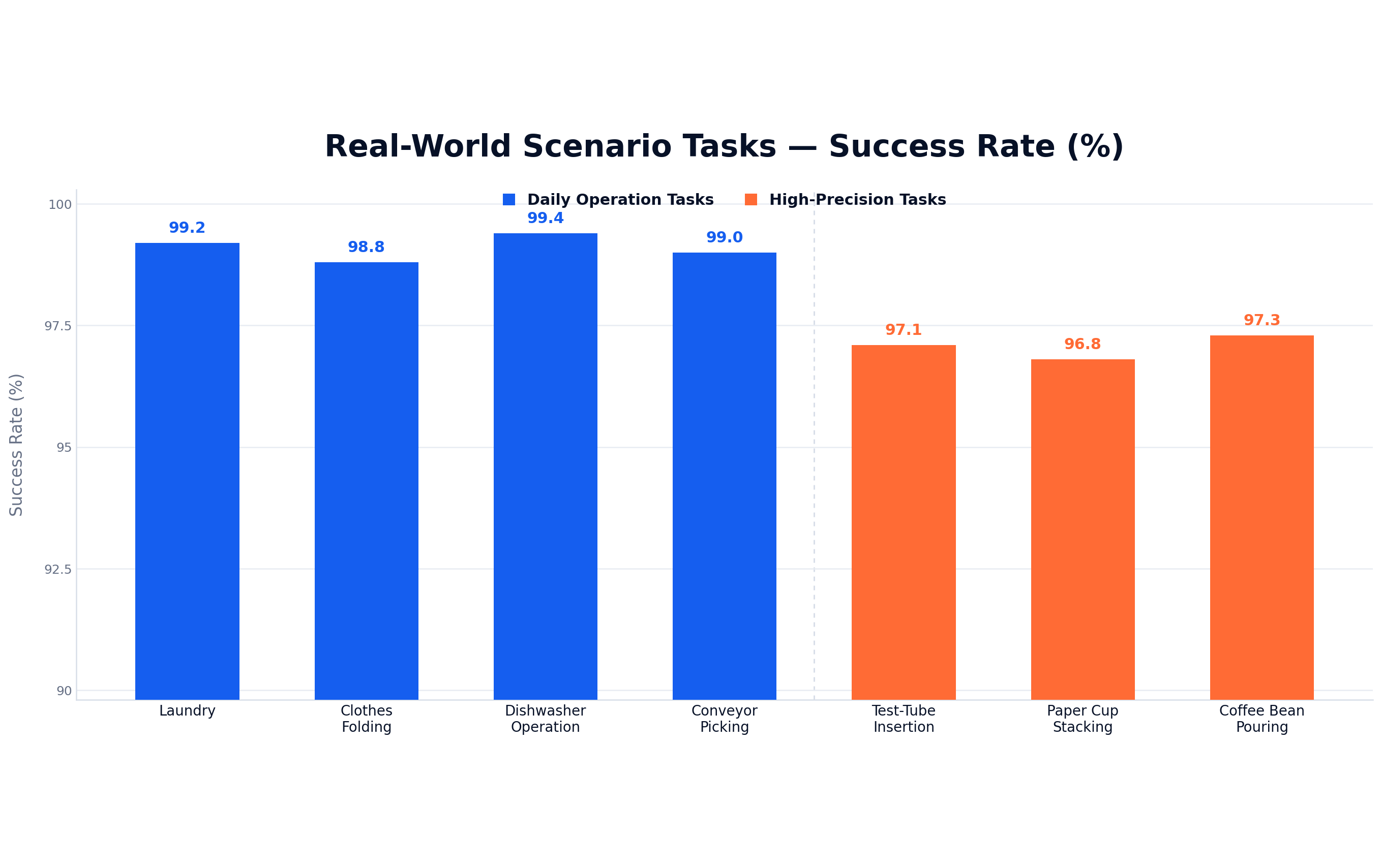
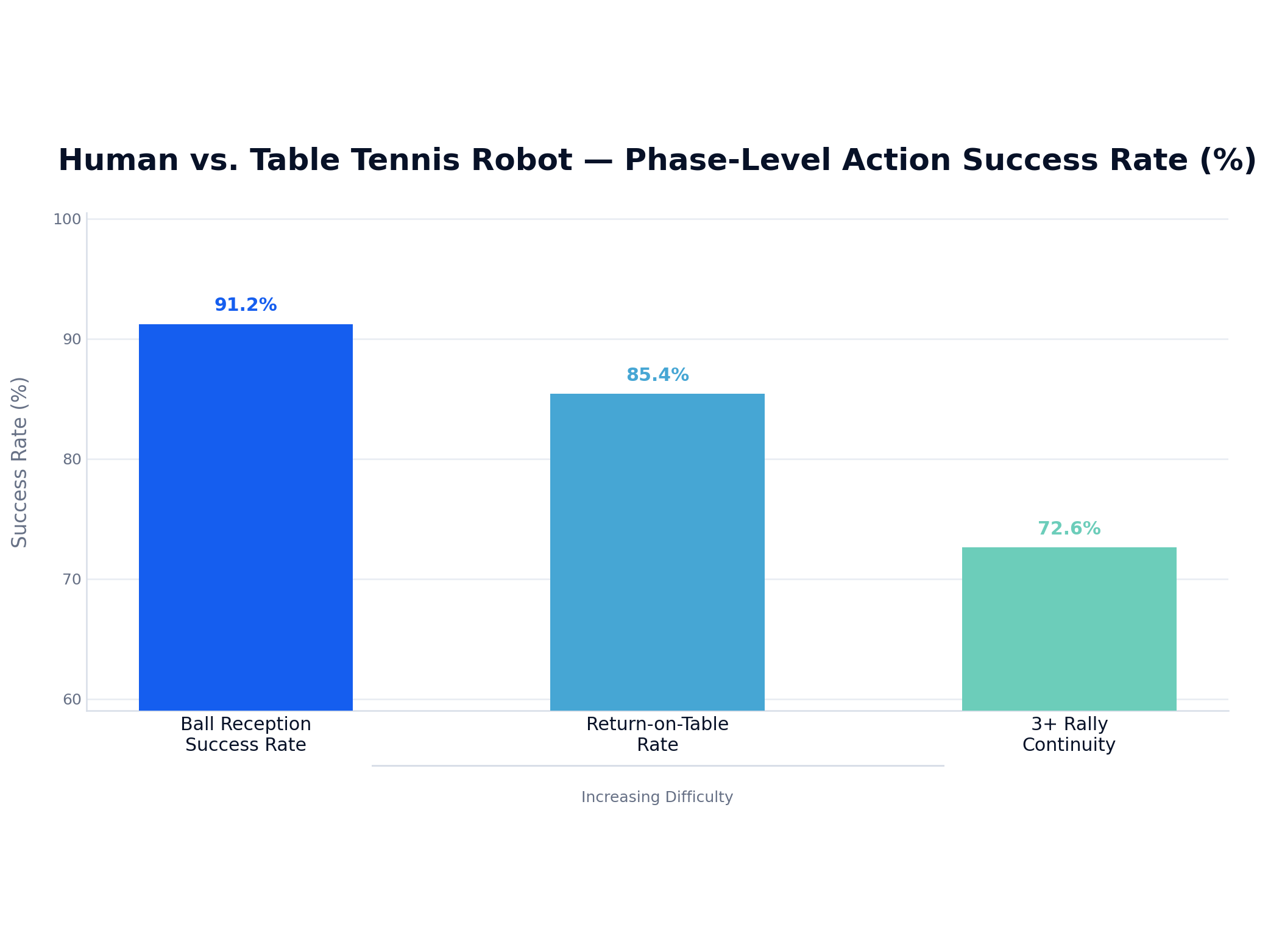
Part 03
OneModel 1.7 FrontoStria-RL: Model Architecture
Overall Architecture
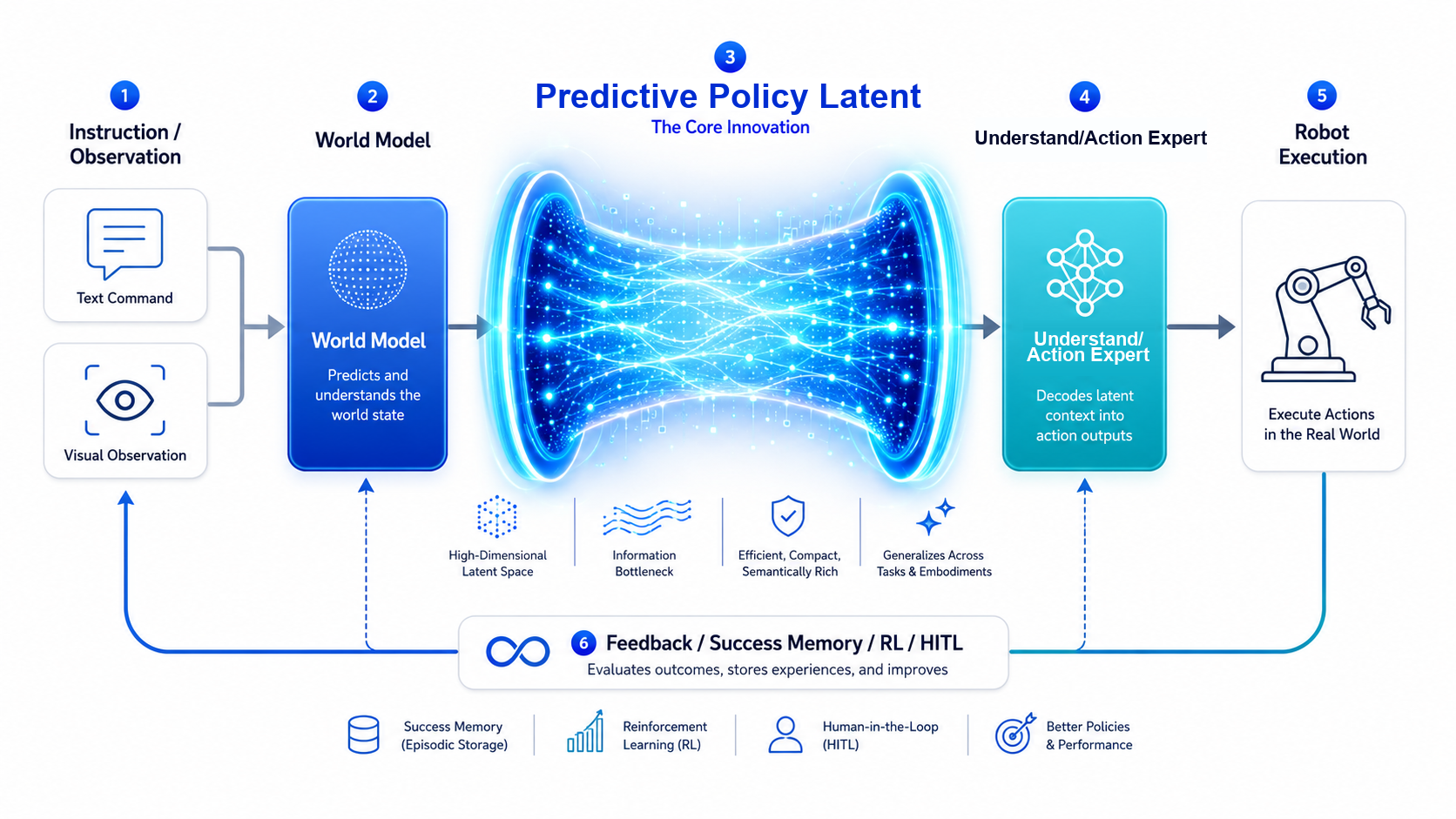
OneModel 1.7 FrontoStria-RL adopts the RL-Latent World Action Model (RL-LWAM) architecture. Its complete information flow is as follows:
Instruction / Observation / Skill → World Model → Predictive Policy Latent → Understand Expert → Action Expert → Robot Execution → RL / Success Memory / HITL ↺
OneModel 1.7 uses the RL-LWAM architecture to form a complete embodied intelligence closed loop: the World Model builds a generalizable representation of the environment; Predictive Policy Latent implicitly transmits that representation to the Understand Expert for task decomposition and Skill scheduling; the Action Expert then generates and executes precise actions. Execution results are used for policy optimization through reinforcement learning, successful experiences are written into memory for later reuse, and human-in-the-loop supervision provides safety constraints - forming an auditable, controllable, and continuously improving loop.
World Model: Understanding the World to Build Generalization
The World Model is the architecture's cognitive layer. It receives environmental observations from visual sensors and natural-language task instructions, then builds a deep understanding of the current scene, including object recognition, spatial-relation reasoning, task-stage decomposition, and action-consequence estimation.
The World Model is the core source of the system's generalization capability. Even in unseen scene layouts or with unfamiliar manipulation objects, the system can still form reasonable high-level task plans - exactly the capability that purely end-to-end action mapping struggles to cover reliably.
Predictive Policy Latent: Implicit Transmission Across the Full Chain
The World Model's understanding must be transmitted to downstream modules before it can create value. Traditional approaches often rely on explicit intermediate representations, such as generated future images or target coordinate points, but these representations lose information, create tight coupling, and struggle to carry the rich, abstract understanding produced by a World Model.
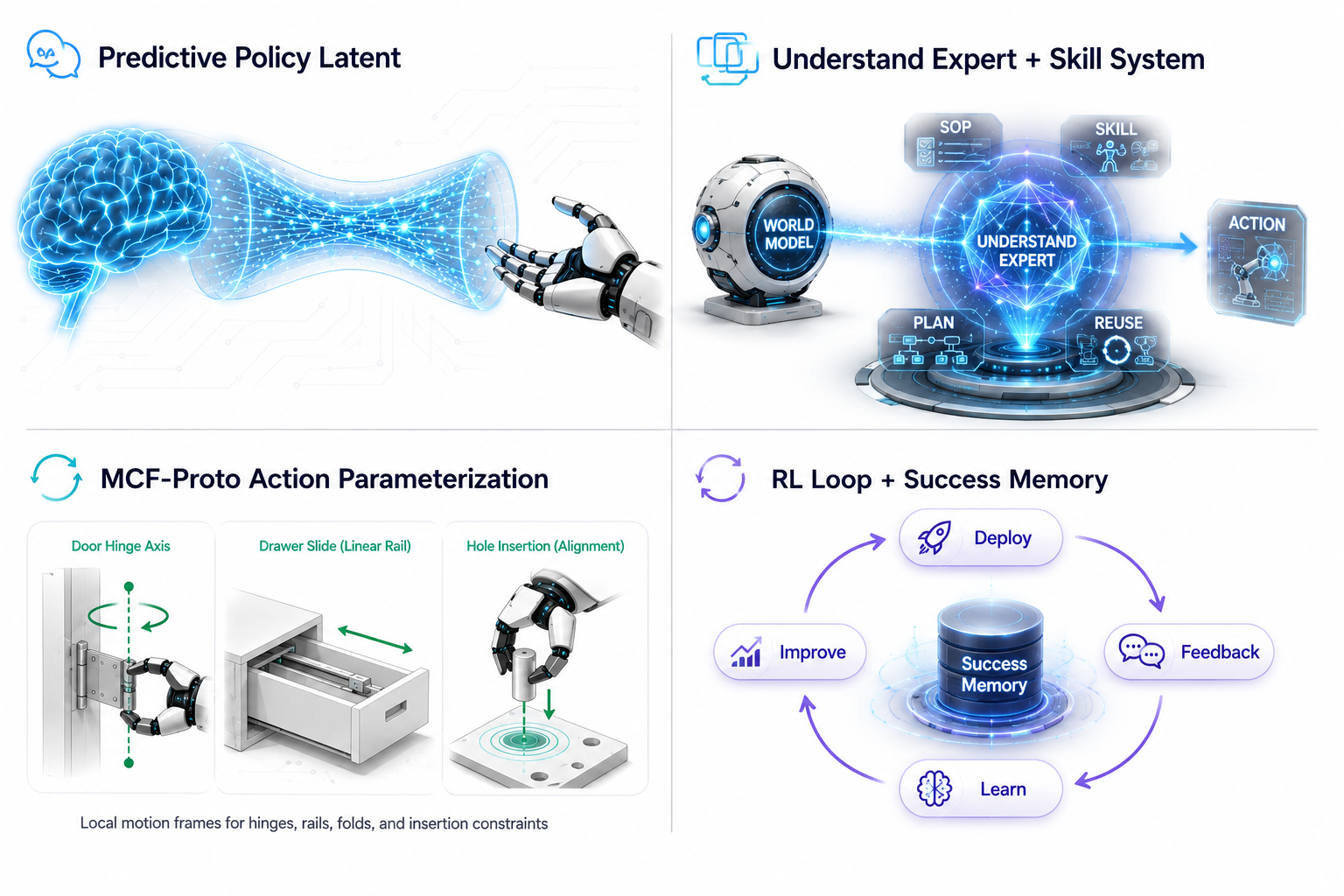
One core innovation of RL-LWAM is the use of Predictive Policy Latent - an implicit policy modulation layer - to connect the World Model, Understand Expert, and Action Expert. Here, the latent is not an image or a set of explicit coordinates. It is a physical-reasoning representation learned during training with the help of future observations: during training, the model can "see" the result after an action is executed, shaping its understanding of task consequences; during deployment, it no longer depends on future information and can form equivalent action expectations from current observations alone. It transfers the World Model's understanding of scene structure and motion trends to the Understand Expert and Action Expert in a compressed, efficient, and learnable form.
This mechanism allows high-level generalizable understanding to efficiently drive task decomposition and action execution. Compared with explicit image generation, implicit modulation skips redundant pixels and generative noise, preserving only the information that truly matters for decision-making.
Understand Expert: Task Decomposition and Skill Scheduling
The Understand Expert is the architecture's planning layer. It receives modulation signals from Predictive Policy Latent and performs structured decomposition of the current task - identifying task stages, determining subgoal dependencies, and scheduling the corresponding Skill sequence - so the robot always knows which stage it is in and what to do next when facing complex long-horizon tasks.
This module enables the system to reuse existing Skills for new task combinations instead of learning from scratch each time. In long workflows, it preserves goal consistency and avoids losing the global objective due to disturbances in intermediate steps.
Action Expert: Precise Actions to Ensure Success Rate
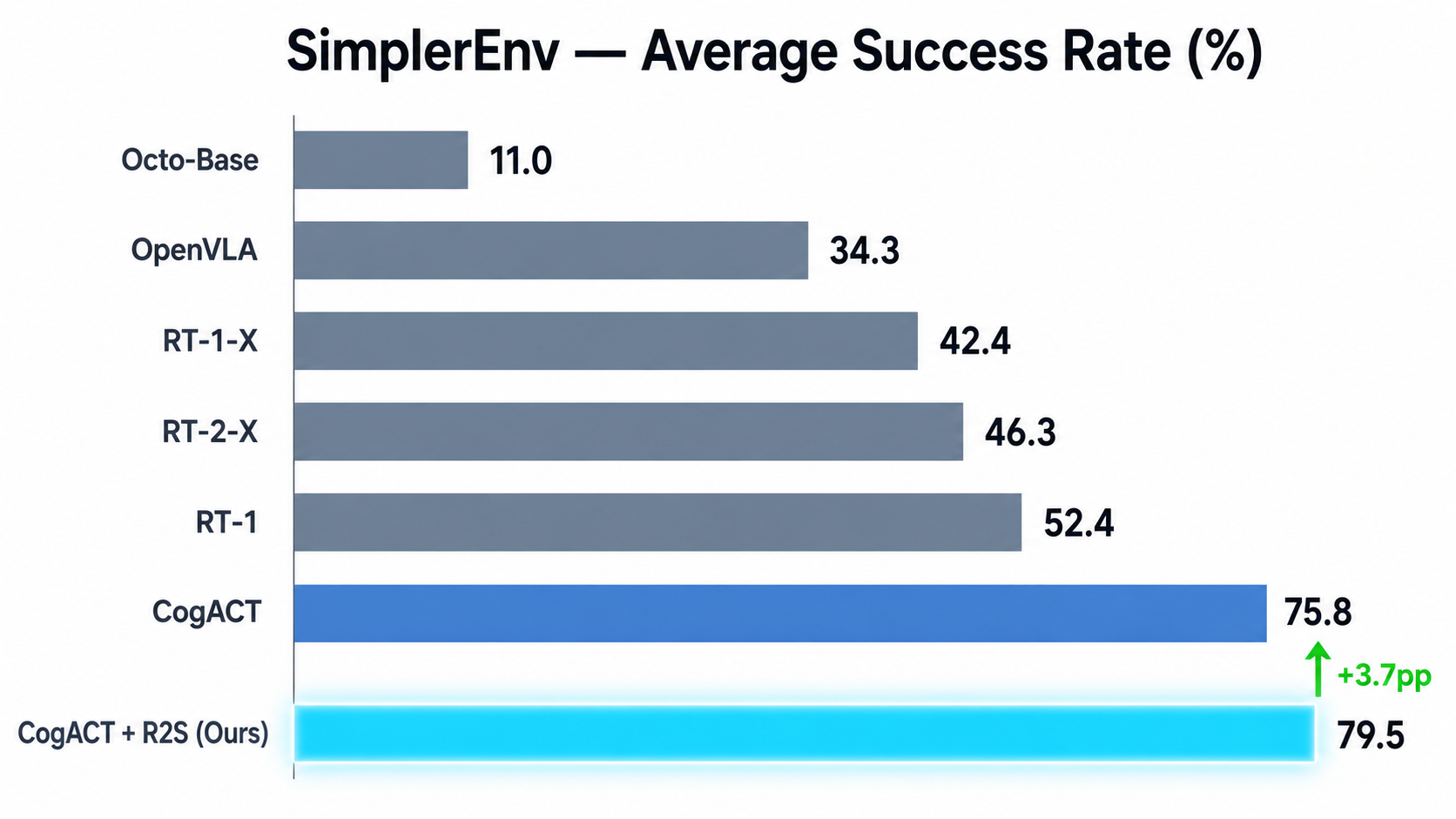
The Action Expert is the architecture's execution layer. It receives Skill instructions from the Understand Expert and real-time visual observations, then generates continuous action plans through flow matching. The model does not learn single-step absolute displacement; it learns a continuous velocity field from noise to real action, generating a complete action sequence, or action chunk, which is then converted by the robot adapter into executable robot commands.
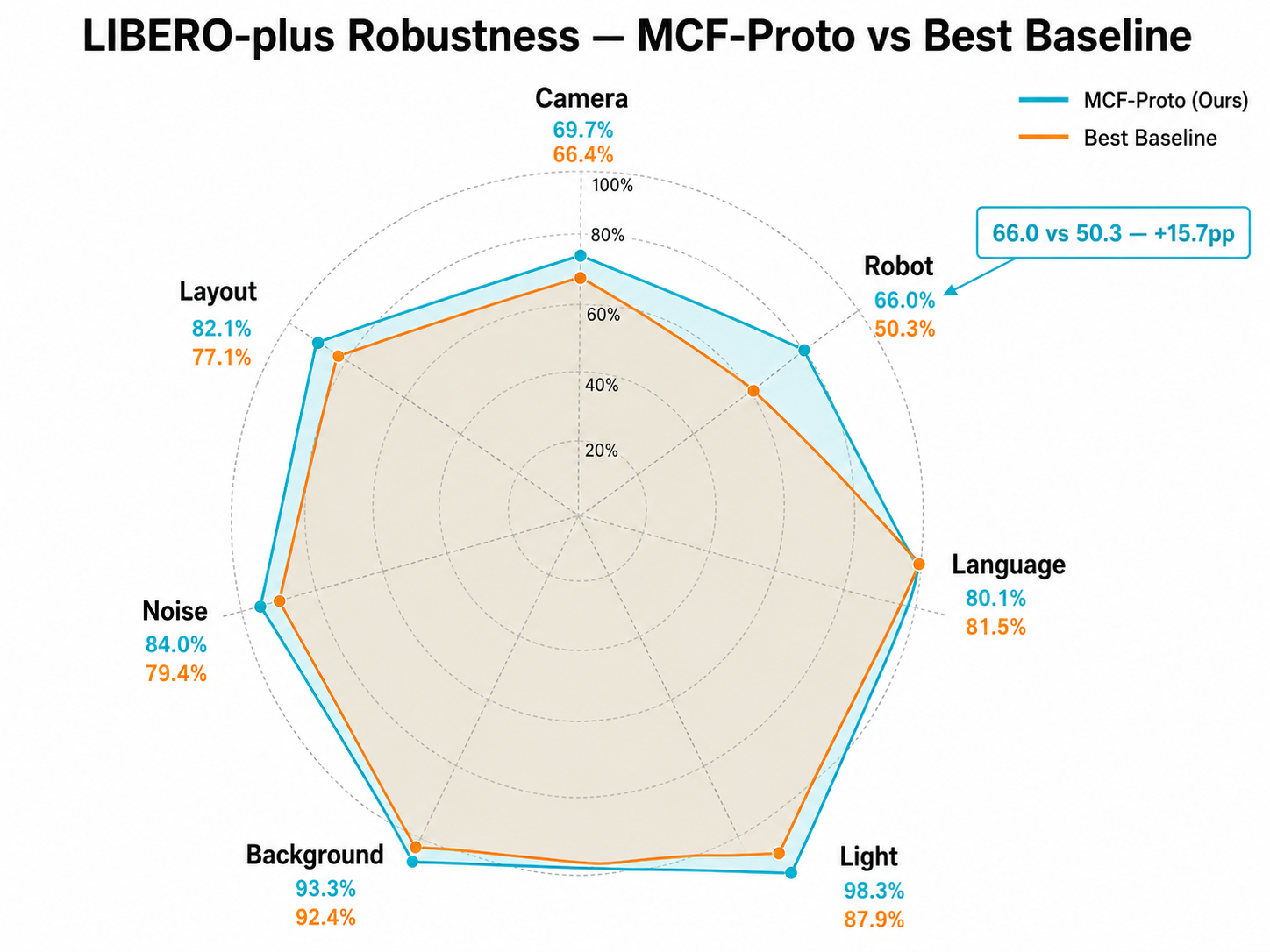
At the action-parameterization level, OneModel 1.7 further adopts MCF-Proto (Motion-Centric Action Frame): instead of directly predicting displacement in a fixed world coordinate system, it organizes action prototypes around task-relevant local motion structures - such as door hinges, rails, holes, and folding lines - then maps them back to real robot actions. This design keeps action generation highly stable under camera-view perturbations and robot initial-pose deviations.
Reinforcement Learning Closed Loop and Success Memory: Continuous Evolution
In real deployment, no model can be perfect on day one. OneModel 1.7 builds a complete continuous-optimization loop into the architecture.
Reinforcement learning (RL) uses real task feedback for autonomous exploration and policy optimization, enabling the model to go beyond imitation and discover better execution paths.
Success Memory, based on Retrieve-then-Steer, writes action segments that succeed during deployment into an online memory bank. When a similar scenario appears again, the system automatically retrieves verified successful experience to guide the next round of action generation, improving success rate without updating model parameters.
Human-in-the-loop supervision (HITL) provides safety constraints for high-risk tasks, balancing autonomous RL exploration with safety boundaries. Together, these components form a continuous-evolution engine that improves through use.